Parameter Efficient Fine-tuning
PEFT는 모델의 모든 파라미터를 학습하지 않고, 일부만 효율적으로 학습하여 자원과 시간을 절약하면서도 높은 성능을 유지할 수 있는 방법론이다.
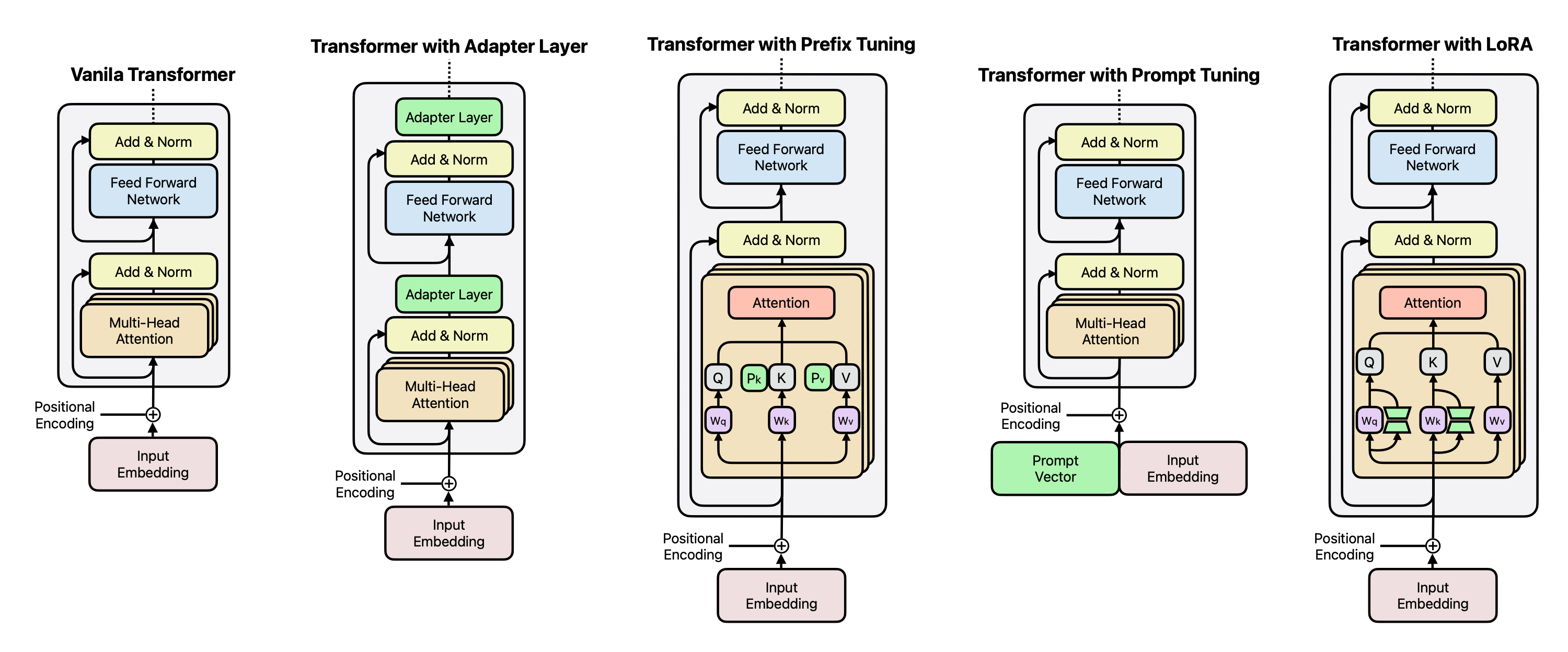
1. 어댑터 튜닝(Adapter Tuning)
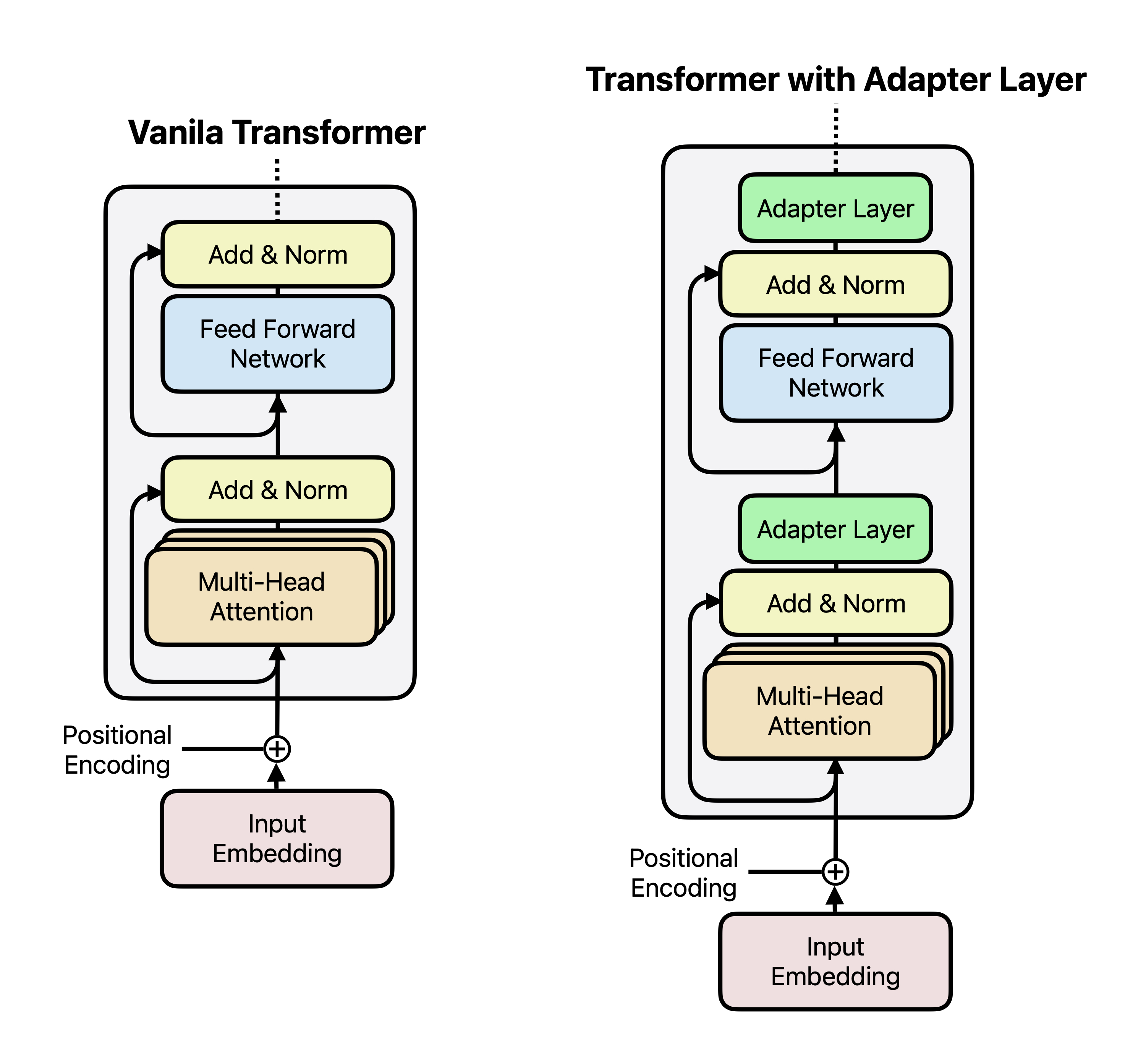
어댑터 튜닝은 트랜스포머 모델의 일부(멀티헤드 어텐션Multi-Head Attention과 피드포드 네트워크FeedForward-Network) 사이에 새로운 “어댑터 레이어”를 추가하는 방식이다. 기존 모델은 고정하고, 어댑터 레이어만 학습하여 자원을 절약다.
Code
from transformers import AutoModel, AdapterConfig
# 어댑터 설정
config = AdapterConfig.load("pfeiffer", reduction_factor=16)
model = AutoModel.from_pretrained("bert-base-uncased")
# 어댑터 추가 및 활성화
model.add_adapter("adapter_name", config=config)
model.train_adapter("adapter_name")
2. 프리픽스 튜닝(Prefix Tuning)
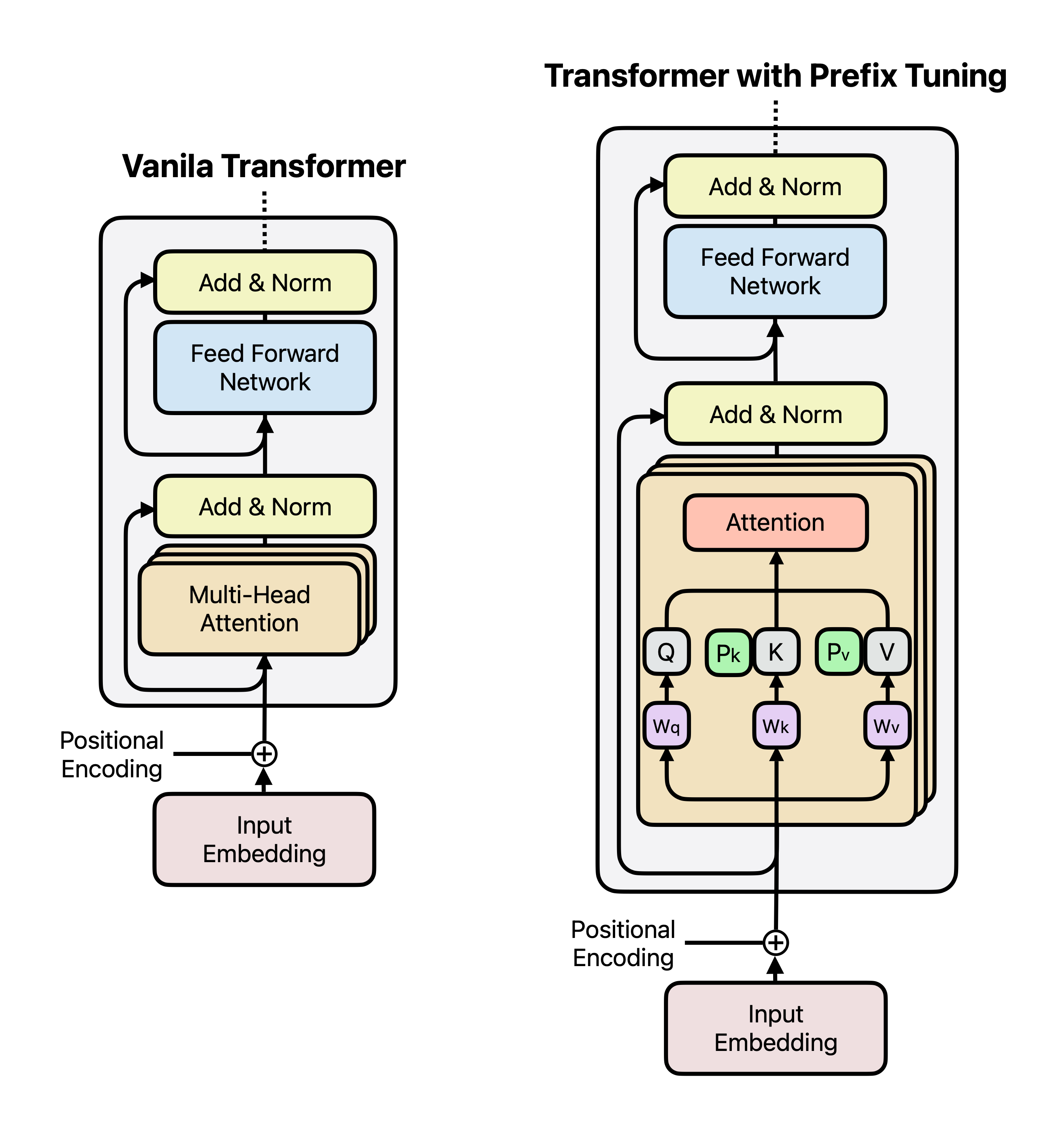
프리픽스 튜닝은 트랜스포머 각 레이어에 “프리픽스 벡터”를 추가한다. 기존 모델은 그대로 두고, 프리픽스만 학습한다.
Code
from peft import PrefixTuningConfig
# 프리픽스 튜닝 설정
config = PrefixTuningConfig(
num_virtual_tokens=10,
encoder_hidden_size=768,
prefix_projection=True
)
# 기존 모델에 프리픽스 적용
model = AutoModel.from_pretrained("bert-base-uncased")
model.add_adapter("prefix_tuning", config=config)
model.train_adapter("prefix_tuning")
- 적용 대상: 텍스트 생성(task-specific generation) 테스크.
- 특징: 프리픽스 수(
num_virtual_tokens)는 테스크 복잡도에 따라 조정.
3. 프롬프트 튜닝(Prompt Tuning)
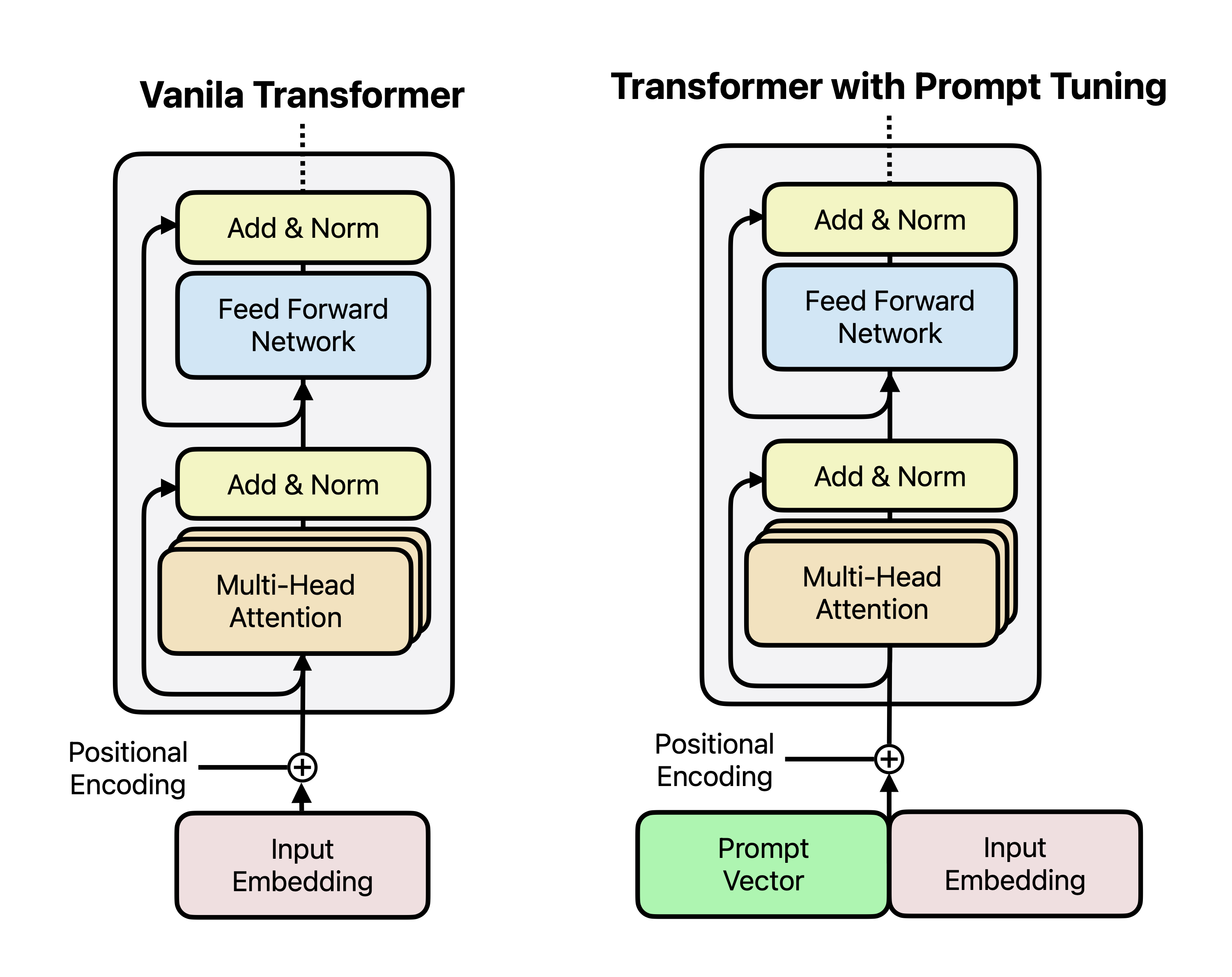
프롬프트 튜닝은 입력 문장 앞에 “훈련 가능한 프롬프트 벡터”를 추가하는 방식이다.
Code
from peft import PromptTuningConfig
# 프롬프트 튜닝 설정
config = PromptTuningConfig(num_virtual_tokens=20)
# 기존 모델에 프롬프트 적용
model = AutoModel.from_pretrained("bert-base-uncased")
model.add_adapter("prompt_tuning", config=config)
model.train_adapter("prompt_tuning")
- 적용 대상: 분류, 감정 분석 같은 단순 테스크.
- 조정할 값:
num_virtual_tokens는 프롬프트 길이를 결정.
4. 로우 랭크 어댑터(Low-Rank Adapter, LoRA)
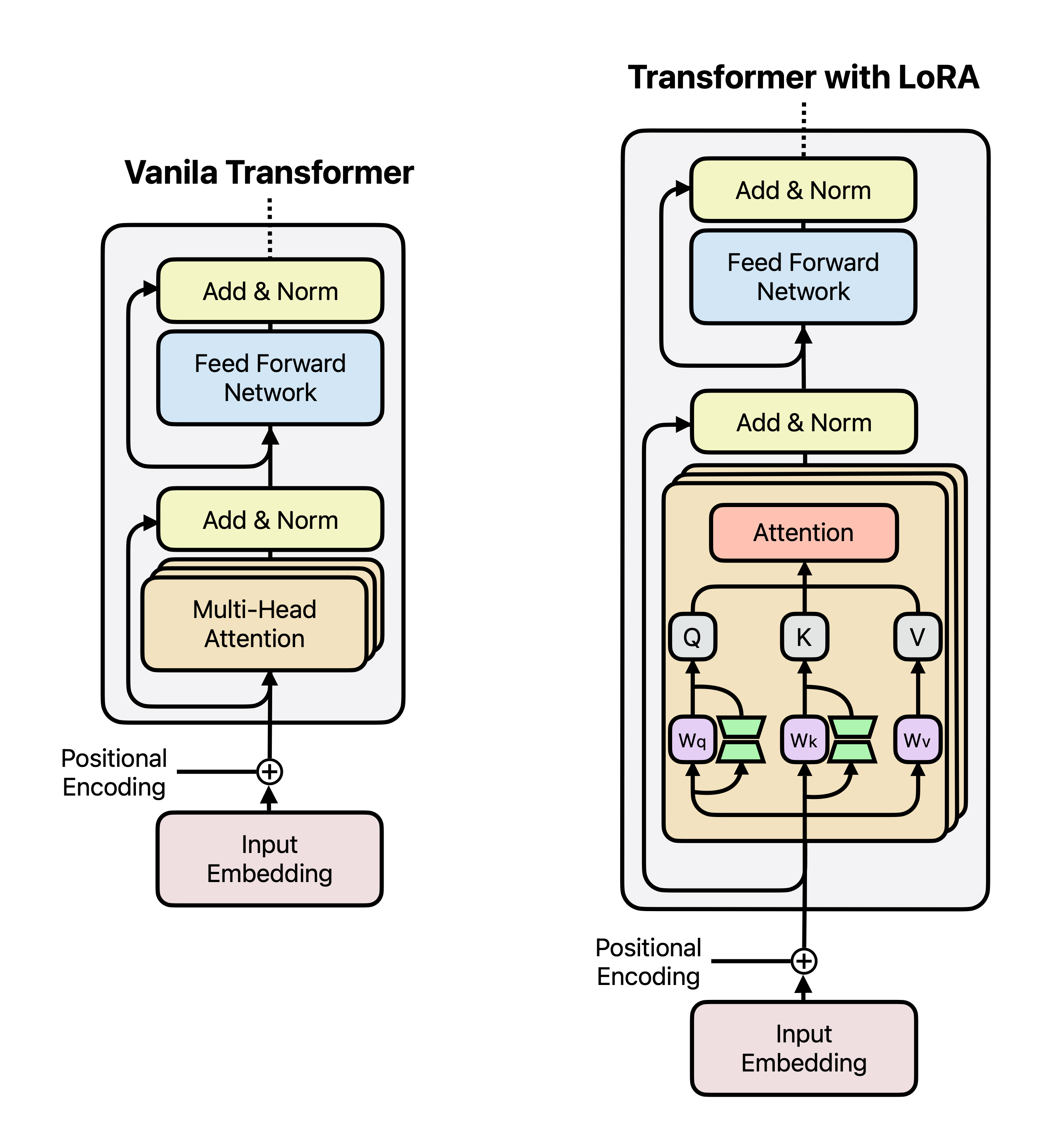
LoRA는 모델 파라미터를 “작은 차원(r)의 행렬”로 나누어 학습하는 방식이다. 기존 파라미터는 고정하고 작은 크기(r)만 학습하여 효율성을 높인다.
Code
from peft import LoRAConfig
# LoRA 설정
config = LoRAConfig(
rank=4,
alpha=32,
dropout=0.05,
target_modules=["query", "value"],
)
# 모델 로드 및 LoRA 적용
model = AutoModel.from_pretrained("bert-base-uncased")
model.add_adapter("lora", config=config)
model.train_adapter("lora")
- 적용 대상: GPT 같은 대규모 모델.
- 조정할 값:
rank: 파라미터 학습의 세부 정도를 조절alpha: 스케일링 파라미터로, 일반적으로 rank의 8배로 설정target_modules: LoRA를 적용할 특정 모듈 지정 (예: “query”, “value”)dropout: 과적합 방지를 위한 드롭아웃 비율 설정
| 기법 | 주요 특징 | 주요 사용 사례 |
|---|---|---|
| Adapter Layer | 모델 구조에 추가적인 레이어 삽입. 업/다운 프로젝션으로 파라미터 효율적 학습. | 다중 태스크 학습(예: 질의응답 + 텍스트 분류), 저자원 환경(저자원 언어 번역), 태스크 전이 학습(BERT → 도메인 특화 분류). |
| Prefix Tuning | Key와 Value에 프리픽스 벡터를 추가하여 특정 태스크 적응. 입력과 파라미터는 고정. | 텍스트 생성(예: 대화 생성), 번역(저자원 언어 포함), 요약 등 대규모 언어 모델 기반 생성 태스크에서 주로 활용. |
| Prompt Tuning | 입력 앞에 학습 가능한 프롬프트 벡터를 추가하여 태스크 적응. 간단한 입력 구조에 적합. | 감정 분석, 텍스트 분류, Few-shot 학습(예: 소규모 데이터로 특정 태스크 적응), 입력 구조가 단순한 태스크에서 주로 사용. |
| LoRA | 가중치 행렬에 저차원 업데이트를 추가하여 효율적으로 학습. 모델 구조 변경 없음. | 대규모 모델의 Fine-tuning(예: GPT-3, T5), 제한된 리소스 환경에서 효율적 학습, 텍스트 생성(번역, 요약). |
댓글남기기